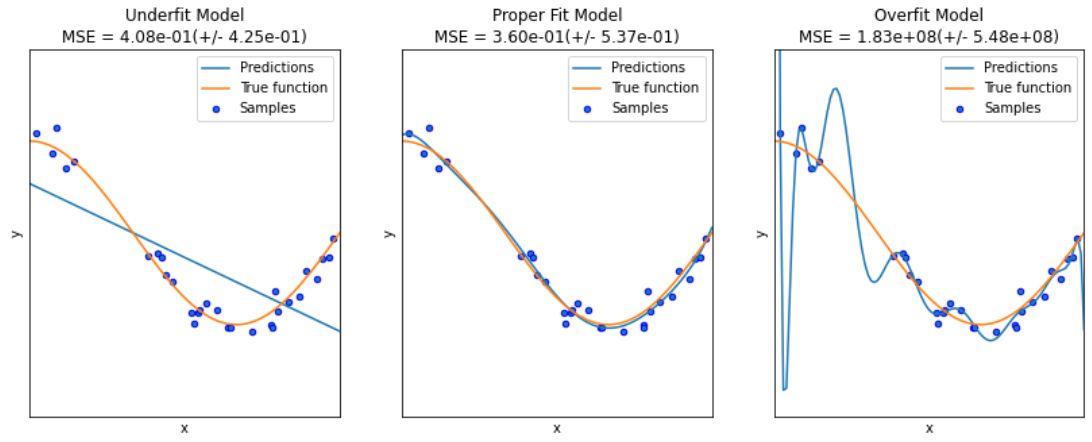
模型全景
From Simple to Complex: A Journey Through Linear Models
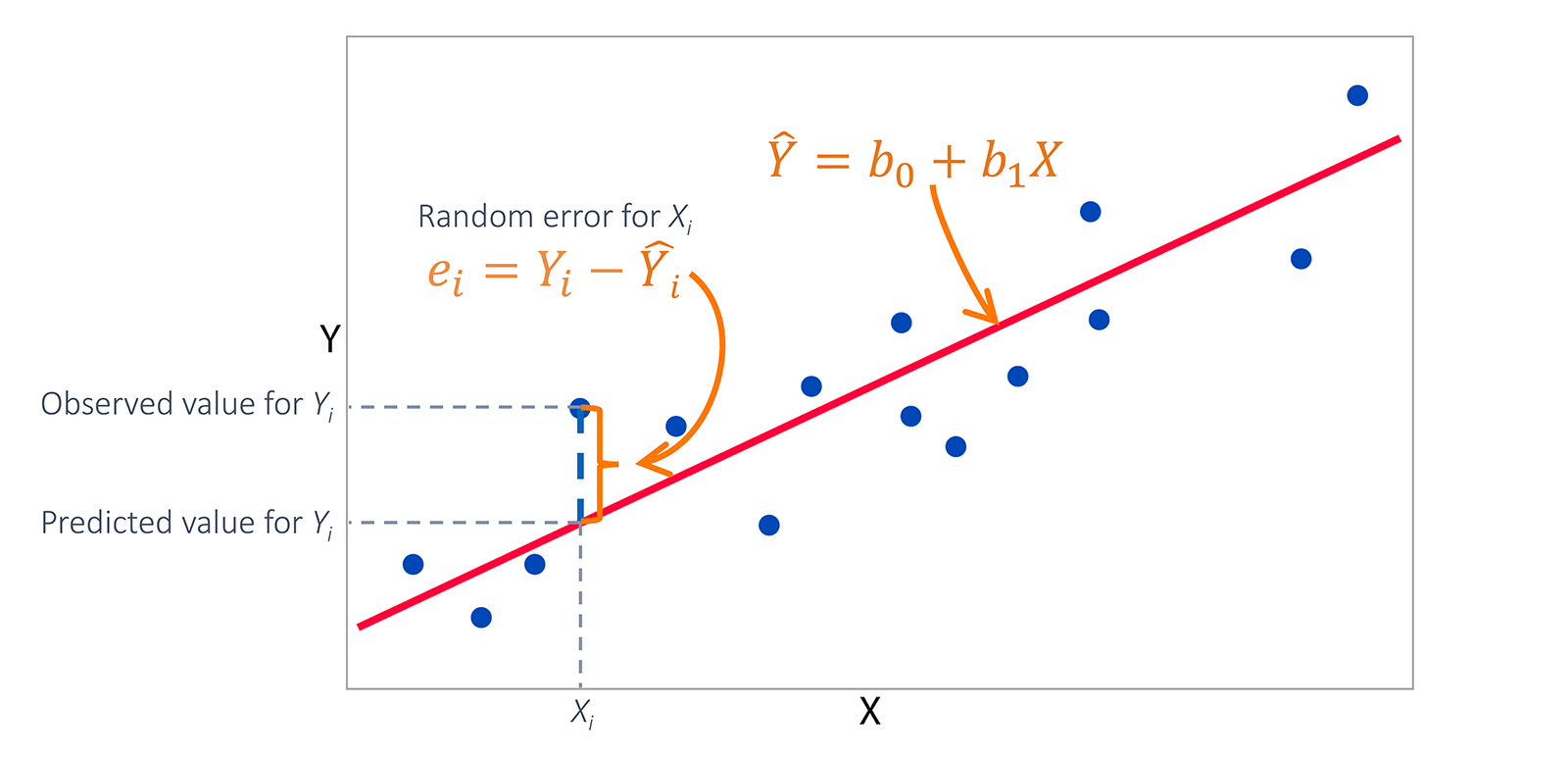
线性回归
Linear Regression
最小二乘法寻找最佳拟合直线,通过最小化预测值与实际值之间的平方误差来确定模型参数。
核心公式
y = θ₀ + θ₁x₁ + ... + θₙxₙ
损失函数
J(θ) = ½m⁻¹Σ(hθ(x)-y)²
逻辑回归
Logistic Regression
通过Sigmoid函数将线性输出映射到概率空间,解决分类问题。
梯度下降
Gradient Descent
迭代优化算法,通过计算梯度方向逐步找到损失函数的最小值。
岭回归
Ridge Regression (L2 Regularization)
添加L2正则化项防止过拟合,通过惩罚大的参数值来提高模型的泛化能力。
J(θ) = MSE + λΣθ²
Lasso & 弹性网络
L1 Regularization & Elastic Net
Lasso通过L1正则化实现特征选择,弹性网络结合L1和L2的优势。
Lasso:
J(θ) = MSE + λΣ|θ|
Elastic Net:
J(θ) = MSE + λ₁Σ|θ| + λ₂Σθ²
模型对比
Model Comparison
特征选择
解释性
抗过拟合